
LLM Large Language Models in esecuzione locale
Ovvero senza una connessione ad Internet richiesta come nel caso di ChatGPT con una attenzione particolare alla privacy dell’utente.
I modelli di apprendimento basati sulla comprensione del linguaggio naturale, umano vengono addestrati dai loro progettisti attingendo ad enormi basi di dati sia online (Internet) che offline ovvero anche mediante acquisizione di documenti, libri, testi in formato proprietario Adobe .pdf o testuale.
GPT4ALL e’ disponibile per sistemi operativi a kernel Linux come Ubuntu, Microsoft Windows e macOS. Richiede per una esecuzione ottimale almeno 16 GiB di memoria centrale, fisica RAM (Random Access Memory) e spazio su disco per ospitare i modelli di apprendimento la cui dimensione si aggira attorno ai 4 GiB circa, l’uno.

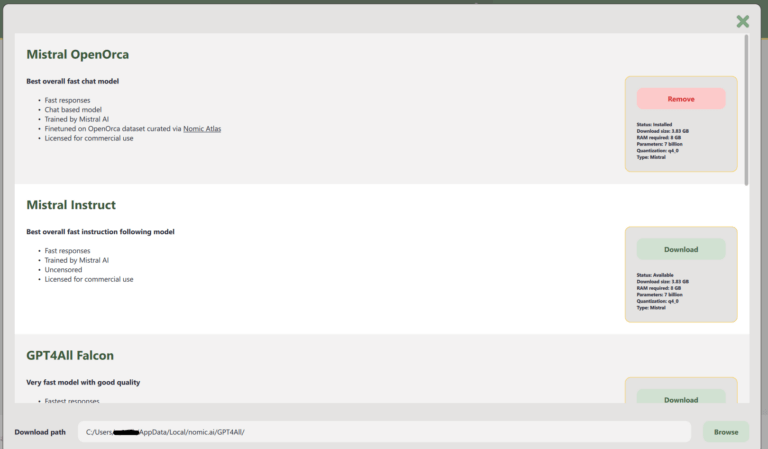
I modelli di GP4ALL
Ogni modello può variare in accuratezza e dimensioni, richiedendo diverse risorse di calcolo e memoria. Ad esempio il modello Mistral Open Orca, che occupa 3.83 GiB e contiene 7 miliardi di parametri. Questo modello verrà scaricato come file con estensione “.gguf”, trattandosi di un’intelligenza artificiale pre-addestrata.
Quando parliamo di modelli, ci riferiamo ai parametri che ne definiscono la complessità. Un numero maggiore di parametri indica un modello più preciso ed efficiente nel riconoscimento dei testi. Ad esempio, ChatGPT 4.0 possiede 100.000 miliardi di parametri, ovvero pesi che determinano le connessioni tra i neuroni artificiali, rispetto ai 175 miliardi di ChatGPT 3.5. È evidente, quindi, che il modello utilizzato in GPT4All è significativamente meno complesso.

